Importing Repeating Row Data
If your ExtraView installation is configured to use repeating rows within the defined process, special consideration must be given in preparing the input file, to describe the repeating row fields, and to provide the data for the repeating rows. This diagram shows the structure if there is a single repeating row within each issue:
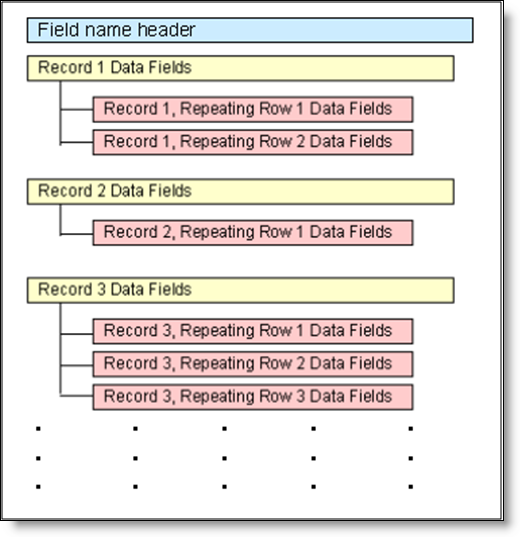
Structure of the import file
Within the import file that you create, this is reflected as shown in this screenshot of Excel, being used to prepare a comma separated value file:
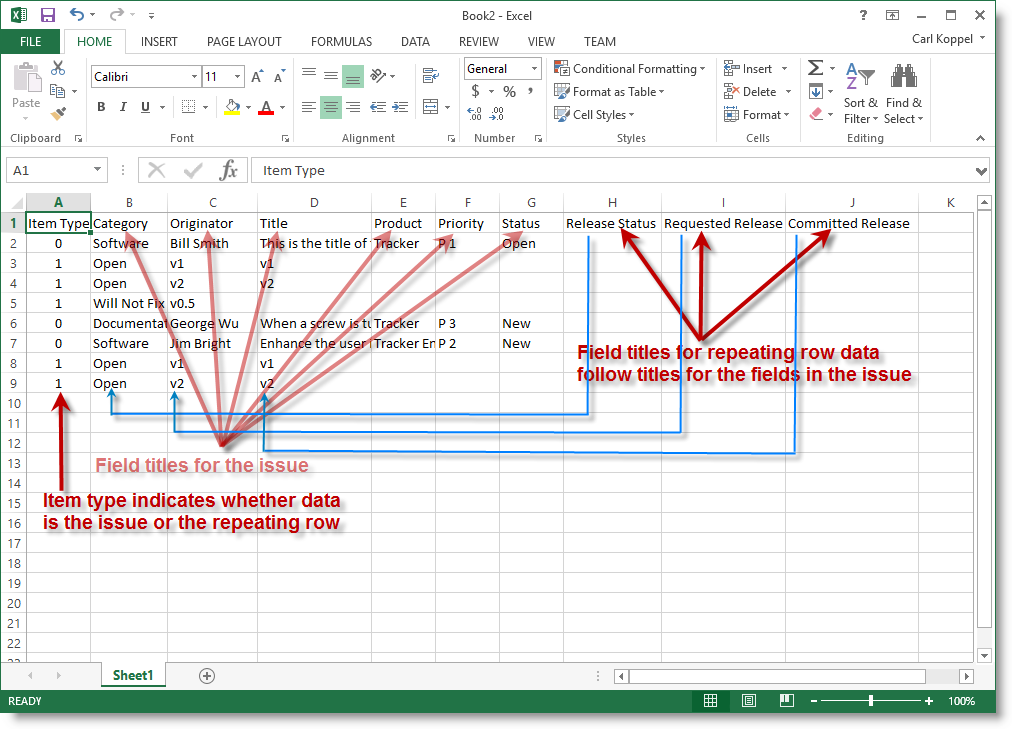
Import file with repeating row data
Note the presence of the first column with the title of Issue Type. A value of 0 indicates the row contains the issue field data. A value of 1 indicates that the row contains data for a repeating row. The 1 value is used for the built-in RELEASE repeating row. You will provide a different (arbitrary) number for repeating row layout types that you have created.
The red arrows point to the field titles, first for the issue itself, and then for the repeating row field titles. The blue arrows show how the repeating row data values are then inserted into the spreadsheet as rows following the issue. There may be any number of repeating rows inserted for any issue.
Note these differences when preparing a file for import that contains repeating rows compared to a file that only has issue data:
-
Header Row
- The header row with the field names must begin in the first column with the value Item Type or ITEM_TYPE_ID. Item Type is the title and ITEM_TYPE_ID is the name. These terms are synonymous for the purpose of preparing the input file and can be used interchangeably
- You place each of the field names (or titles) to be imported on the first row of the spreadsheet. First, you will have all the field names / titles for the main issue data in the order that the data will appear within the data rows
- Next you will have all the field names / titles for each of the fields within the repeating row, in the same order they will appear within the data rows of the spreadsheet. Placing these once on the header row negates the need to repeat these for each series of repeating rows within the data rows of the spreadsheet
-
Data Rows
-
Each row in the data must begin with the type of data on the row. The valid entries are either:
- a 0 to represent Issue Item rows or
- an ITEM_GROUP_TYPE_ID or its File Marker, to represent Repeating Row Items. See the next section on this page for an explanation of the File Marker
- You can see from the above example that these all appear with the header row of the column being Item Type. An ITEM_GROUP_TYPE_ID value of 1 represents the built-in RELEASE repeating row type
- The first data row of each issue will be an Issue Item row with a value of 0, followed by its set of repeating rows. The remaining columns of the first data row will be the field values for the main issue fields. Each of the field values will thus appear within the spreadsheet column whose header row is the field name or field title to the field value
- You may now create any number of rows with the Repeating Row Item Group type of an ITEM_GROUP_TYPE or one of its File Markers. For each row that is of a repeating row type, a new repeating record will be created within the main issue. You begin the value data for each repeating row in column B of the spreadsheet, and place the values in the same order as the field names / titles were entered into the Header Row
- For each issue you are inserting, with its set of repeating rows, repeat the steps in this section starting in the next blank row of the spreasheet.
-
Each row in the data must begin with the type of data on the row. The valid entries are either:
Repeating row data stored within ExtraView issues may or may not have a unique identifier for each row of data. This is controlled with the behavior setting named ENFORCE_UNIQUE_RELEASES. When this is set to YES, you must:
- Map one field in the repeating row data of ITEM_GROUP_TYPE_ID 1 to be imported to the ExtraView field named RELEASE_FOUND
- Have a unique value of the field being mapped to RELEASE_FOUND for each row in the import file, within each issue
- Have write permission to the RELEASE_FOUND field
Importing Files Which Contain Data for Multiple Repeating Row Types
The preceding information relates to the importing of data which contains a single repeating row Item Type. ExtraView can import files which contain multiple repeating rows within a single file, using an extension of the above methodology.
You adjust the spreadsheet format for each repeating row type you wish to import by simply adding the field titles for each repeating row type in the header row, and then creating a data row for each repeating row type. The Issue Type column provides the indicator as to the repeating row to which the data belongs.
Each repeating row in an ExtraView database has an internal identifier which is not readily seen or displayed to the administrator creating the import file, therefore an intermediate File Marker is used to provide the connection between the field data within the import file and the data being stored within the ExtraView database. Follow this procedure to prepare your import file:
-
Header Row
- Follow the instructions in the preceding section, but simply continue the entries in the header row with the names / titles of the fields for each repeating row type within the data to be imported. Again, these should appear in the order that the value data will appear within the spreadsheet
-
Data Rows
- You arbitrarily select a number for each repeating row type that is to be uploaded. 0 is always the number to be used for the Issue Item rows of data. 1 is always used for the inbuilt RELEASE releating row layout type
- The remaining rows will have their arbitrary number in column A of the spreadsheet. Obviously, each repeating row of a specific type should use the same arbitrary number within the input data values
- You simply use the arbitrary number to identify which repeating row fields are to be associated with the data on the rows within the spreadsheet; these numbers can be mapped to the internal ITEM_GROUP_TYPE numbers representing repeating row types
-
When you see the mapping results within the File Import screen, you will see a connector field for each repeating row type. This has the title File Marker. You see the fields for each repeating row type within the mapping results grid on the screen, and you place the number you used within the spreadsheet you uploaded, within the File Marker field to identify which data rows in the spreadsheet belong to which fields in the header row.
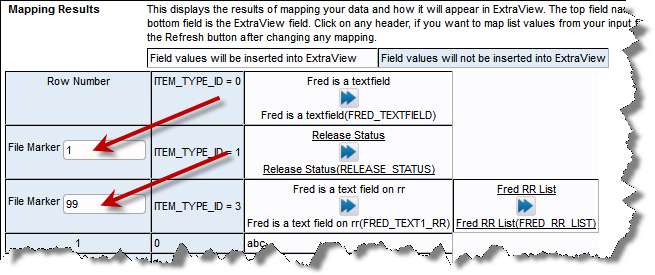
After uploading the spreadsheet with the multiple repeating row types, performing the mapping, and validating the data, you proceed with the file import.