Managing Quickfind
This task automatically indexes newly added text to all issues entered or updated by users in order to speed up keyword searches. Once configured and started, this task will keep the indexes up-to-date as users add or update any text within issues. It also has special properties in better use of wildcards, phrase search, and in the support of Boolean logic within your searches compared to straight SQL searches of your database.
This task defines exactly what text will be indexed, and where the indexes will be stored on the file system of your server. The Quickfind indexing mechanism is based upon the Apache Foundation Lucene technology.
Note that files larger than 16MB in size are not indexed. For full end-user information on the use of Quickfind, see the page titled Keyword Searching.
What is Indexed
The following are indexed as part of Quickfind’s operations.
-
Inbuilt Fields
- the SHORT_DESCR field
-
If the behavior setting named QUICKFIND_INDEX_USERS is YES, the following user fields are indexed:
- OWNER
- ASSIGNED_TO
- LAST_UPDATED_BY_USER
- ORIGINATOR
- CONTACT
- All MODULEs: ASSIGNED_TO field
-
User Defined Fields (UDFs)
- User Defined Field USER type fields
- All User Defined Fields with a display type of TEXTFIELD
- All large User Defined Fields with a display type of TEXTAREA, LOGAREA, PRINT_TEXT
- The User Defined Fields with a display type of HTMLAREA, after removing the HTML tags
-
DOCUMENT fields
- Document description
- File name
-
Document content according to MIME type and content size:
- Size must be less than 16MB
- MIME type must not be any kind of video, audio, or image
- The MIME type is mapped to an extractor – see MIME type extractors below
-
IMAGE fields
- Image description
- File name
-
Attachments – These are indexed by default. If you do not want these indexed, uncomment the appropriate line in the properties file so it reads:
LUCENE_MAX_ATTACHMENTS=0Note that attachments are only searched when the Search Attachment checkbox by the KEYWORD field is checked
-
Attachment content according to MIME type and content size:
- Size must be less than 16MB
- MIME type must not be any kind of video, audio, or image
- MIME type is mapped to an extractor – see MIME type extractors below
- Attachment description is searchable
-
Attachment content according to MIME type and content size:
First-time Setup
If your database contains a significant amount of text, you should follow the process within the Installation Guide, at the page Quickfind before following this page to configure and start the Quickfind task.
The basic setup and configuration of the Quickfind task is accomplished on the Admin ==> Task Manager screen.
- First, Add a new task, and select the Quickfind Synchronization Task
- Select a Node ID on which to run the task. You must not run the task on more than one node within a clustered system. If you do so, you risk corrupting the indexes created with the utility
- Set the Start Option to STOP_NOW. More configuration is required before starting the task
- You can set the frequency with which the task runs with the Poll Interval. It is recommended that this is set between 60 and 600 seconds. The default is 300 seconds
- Do not alter the class name of the task
-
If you enter an absolute path to the index files in the Quickfind Index Location, and the path already exists, the behavior setting named QUICKFIND_INDEX is updated to reflect that path. If the path does not exist when you create the task, the task is still created, but you will encounter an error, and you are taken to the edit mode, where you can correct the path. Suggestions for index names are:
-
C:ExtraView<instance name><index name> on Microsoft Windows platforms,
e.g. C:ExtraViewQuickfindIndex -
/usr/local/extraview/<instance name>/<index name> on Linux and Unix platforms,
e.g. /usr/local/ExtraView/QuickfindIndex - On an NFS mount, include this fact in the index name by using the convention nfs:pathname
-
C:ExtraView<instance name><index name> on Microsoft Windows platforms,
- The behavior setting is updated with the index name you supply
- Click Add to create the task
- Notice that the Task Manager screen now shows the FULL_TEXT_SYNCHRONIZATION Quickfind Synchronize task
-
Click on the Edit button of the Quickfind Synchronize task. You will now see a screen that looks similar to the following:
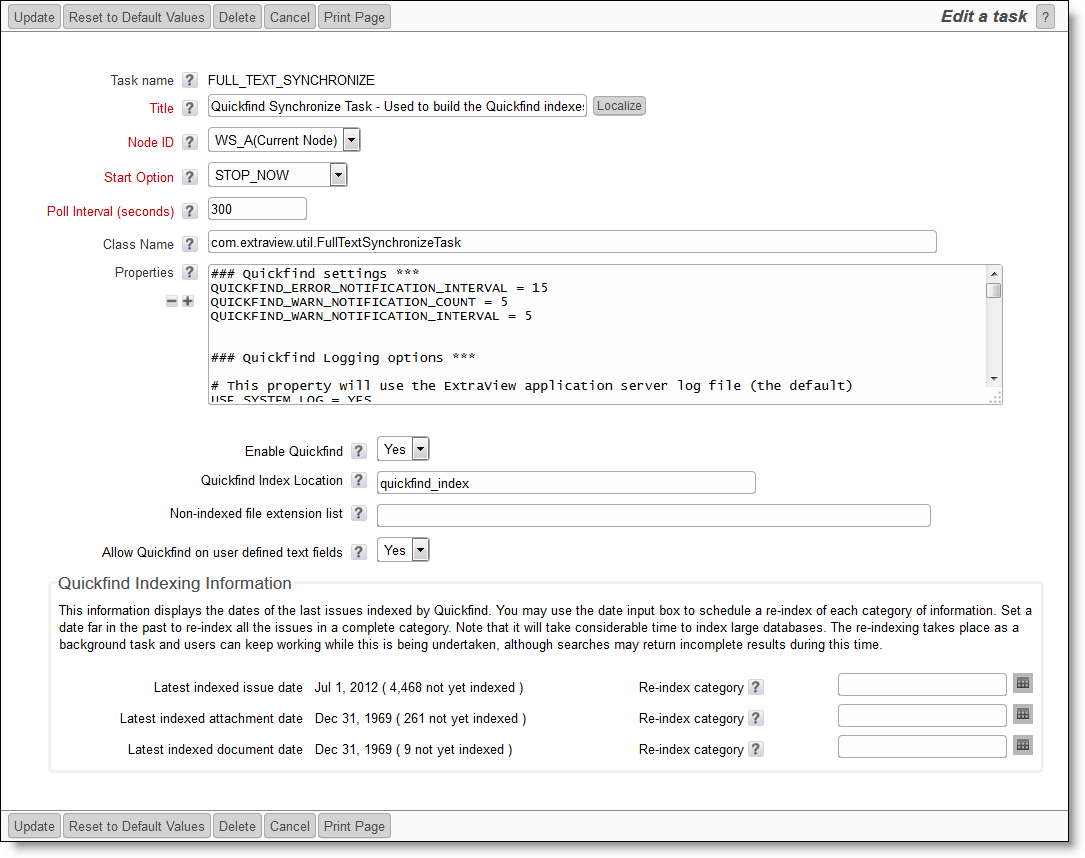
The Quickfind task management utility - Notice the new configuration options that are now displayed
- Set Enable Quickfind to a value of Yes
- Enter the path to the location where the index files are to be stored on your file system. If you will use the default path as explained below, you can skip this step. All application servers within a clustered server environment must have read and write access to the index file location. The index location is also the value stored in the behavior setting named QUICKFIND_INDEX_LOCATION. Further, you must make sure you have sufficient disk space to store the indexes as they grow. The amount of disk space is highly dependent on the quantity of text and number of fields being stored
- The prompt Allow Quickfind on user defined text fields determines whether the text within all the user defined fields should be indexed. The recommendation is that you set this to Yes
- Observe the dates on which files were last indexed, and the count of files still to be indexed
- If this is new site with no issue data, then you may now set the value of the Start Option to START_NOW, and Update. This will start the Quickfind synchronization task and begin to index issues as they are entered by users
- If the site that has existing data and you have not already done so, run the external utility named FullTextIndexSetup. This is described on the page Quickfind in the Installation Guide at the page Quickfind. The utility creates the Quickfind indexes in one fell swoop, in a fast manner. After completing this indexing operation, you can return to this screen, and set the value of the Start Option to START_NOW, and Update
- If you need to re-index all or part of the issue data within your database, the bottom section of the screen provides an aid. You can re-index just the issue data, just the attachments or just the data within document field types, or all of these, by entering a date within each category. To re-index the complete database, put a date in each of the fields, earlier than the date at which data was first entered into the site, and then press Update. On a large site it can take a considerable amount of time to index the data, but your users may continue accessing the site in the meantime. Obviously, some searches may not return complete results. You can use this screen to see the progress and how many items remain to be indexed
- If the behavior setting QUICKFIND_INDEX_ENUMERATED is set to a value of YES, then an additional prompt that allows the administrator to re-index the list field values will also appear on the screen.
Quickfind Properties
The following properties may be set to aid in the running of Quickfind or the investigation of problems:
| Property | Purpose |
| QUICKFIND_ERROR_NOTIFICATION_INTERVAL | The minimum number of minutes between subsequent error email notifications; this prevents multiple emails to the administrator in the case there is a persistent warning condition |
| QUICKFIND_WARN_NOTIFICATION_COUNT | The number of warnings in the warning notification interval before a notification email is sent. It is typically acceptable to have a number of warnings before a warning is sent |
| QUICKFIND_WARN_NOTIFICATION_INTERVAL | The number of minutes in which the warning count specified in QUICKFIND_WARN_NOTIFICATION_COUNT must occur before a notification email is sent |
| USE_SYSTEM_LOG | If this has a value of YES, then the ExtraView application server log file will be used, as opposed to using the log file specified in either LOG_FILE_PATH_NAME or LOG_FILE_PATH_NAME_ABSOLUTE. If this is set to YES, do not use LOG_FILE_PATH_NAME or LOG_FILE_PATH_NAME_ABSOLUTE |
| LOG_FILE_PATH_NAME | The relative pathname to the log file. If this is used, set USE_SYSTEM_LOG to a value of NO and do not use LOG_FILE_PATH_NAME_ABSOLUTE |
| LOG_FILE_PATH_NAME_ABSOLUTE | The absolute pathname to the log file. If this is used, set USE_SYSTEM_LOG to a value of NO and do not use LOG_FILE_PATH_NAME |
| PSP_LOG | Set this to a value of YES if you need to see the SQL statements generated by the task in the log |
| XML_LOG_FLAG | Set this to TRUE if you want the log statements to be generated in XML format |
| DEFAULT_LOG_LEVEL | The default logging level. This is 6 |
| LOG_LEVEL | The log level to use for debugging. In normal operation this should be set to 6 |
| LOG_CHARSET | The character set of the log output. In most cases this should be left as UTF-8 |
| LOG_INCLUDE_THREAD_NAME | This is set to YES to include the threadname of the Quickfind task in the log file |
| LUCENE_MAX_ATTACHMENTS | This should be set to a value of 0 if you do not want to index attachments |
Modifying the Indexing Properties
- Use the Allow Quickfind on user defined text fields selector on the maintenance screen to choose whether to index user defined text fields
- Use the behavior setting named QUICKFIND_INDEX_ENUMERATED to determine whether to index the titles on enumerated text fields
- Use the behavior setting named QUICKFIND_INDEX_USERS to determine whether to index user names within the Quickfind indexes
MIME Type Extractors
There are two text extractors:
- PDF Text Extractor: uses iText PdfReader object to tokenize the PDF strings. Document content will NOT be indexed if it is marked as being “encrypted”
- Office Text Extractor: uses one of the POI extractors appropriate to the type (Word, Excel, Powerpoint, Outlook, Publisher, or Visio). Note: if Excel text extractor fails, it tries to extract text assuming it is a comma-separated or tab-separated text file with an Excel MIME type
- Other MIME type documents are indexed as text
Updating Quickfind
The instructions to update Quickfind are found here.
Notes
As stated above, Quickfind utilizes the Apache Lucene software to provide the indexing mechanism. One support issue is that if your Java Virtual Machine, or your application server (Apache Tomcat or similar) crashes for any reason, then the indexes may be left in a locked state on the server.
The lock files are kept in the directory specified by the org.apache.lucene.lockdir system property if it is set, or by default in the directory specified by the java.io.tmpdir system property (on Unix boxes this is usually /var/tmp or /tmp). If for some reason java.io.tmpdir is not set, then the directory path you specified to create your index is used.
Lock files have names that start with lucene- followed by an MD5 hash of the index directory path. If you are certain that a lock file is not in use, you can delete it manually.