If your ExtraView installation is configured to use repeating rows within the defined process, special consideration must be given in preparing the input file, to describe the repeating row fields, and to provide the data for the repeating rows. This diagram shows the structure:
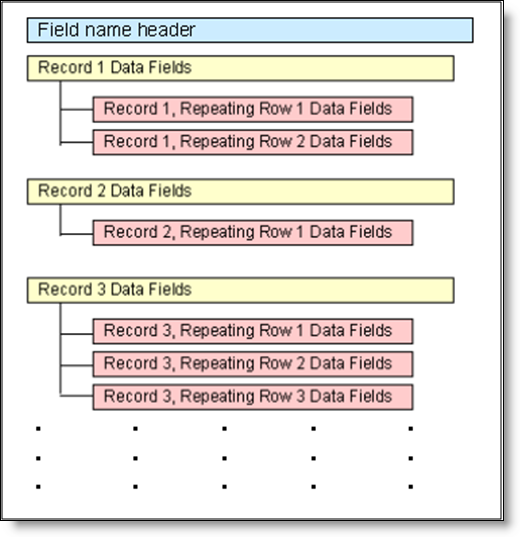
Structure of the import file
Within the import file that you create, this is reflected as shown in this screenshot of Excel, being used to prepare a comma separated value file:
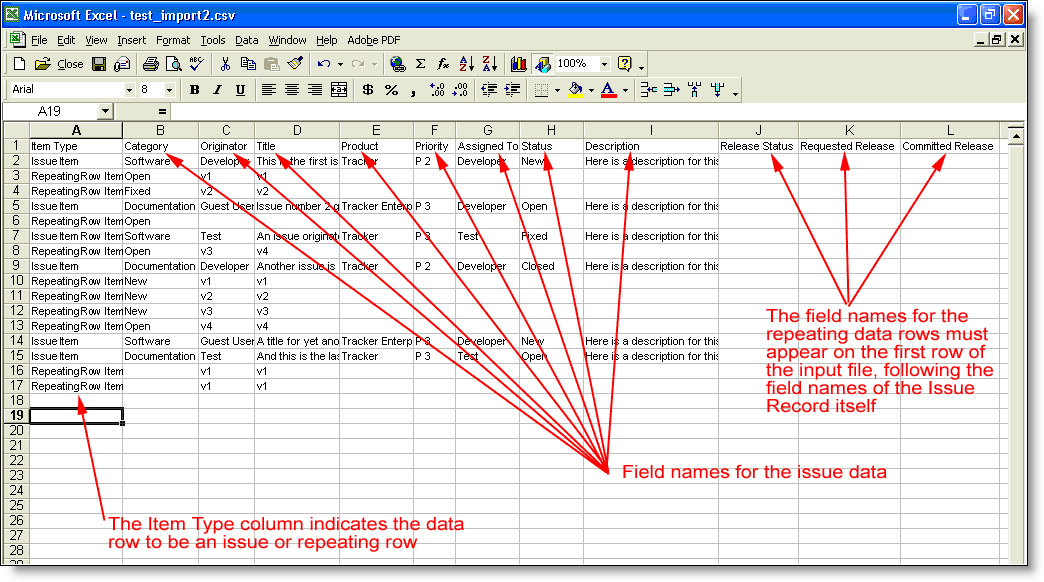
Import file with repeating row data
Note these differences when preparing a file for import that contains repeating rows:
- The header row with the field names must begin in the first column with the value Item Type
- Each row in the data must begin with the type of data on the row. The valid entries are either a 0 to represent Issue Items or a 1 to represent Repeating Row Items
- The next series of columns in the first row of the data contain the field names of the Issue Record data
- The last series of columns in the first row contain the field names of the Repeating Row data. Note that there will not necessarily be any values underneath these row headings
- For each row that is of type Issue Item, place the values for each field underneath the column heading corresponding to the field name
- For each row that is of type Repeating Row Item, places the values of each field name, beginning in the second column of data, directly following the repeating row value.
Repeating row data stored within ExtraView issues may or may not have a unique identifier for each row of data. This is controlled with the behavior setting named ENFORCE_UNIQUE_RELEASES. When this is set to YES, you must:
- Map one field in the repeating row data to be imported to the ExtraView field named RELEASE_FOUND
- Have a unique value of the field being mapped to RELEASE_FOUND for each row in the import file, within each issue
- Have write permission to the RELEASE_FOUND field