This task automatically indexes newly added text to all issues entered or updated by users in order to speed up keyword searches. Once configured and started, this task will keep the indexes up-to-date as users add or update any text within issues.
This task defines exactly what text will be indexed, and where the indexes will be stored on the file system of your server. The Quickfind indexing mechanism is based upon the Apache Foundation Lucene technology.
Note that files larger than 16MB in size are not indexed.
For full end-user information on the use of Quickfind, see the page titled Keyword Searching.
The basic setup and configuration of Quickfind is accomplished on the Admin ==> Task Manager screen.
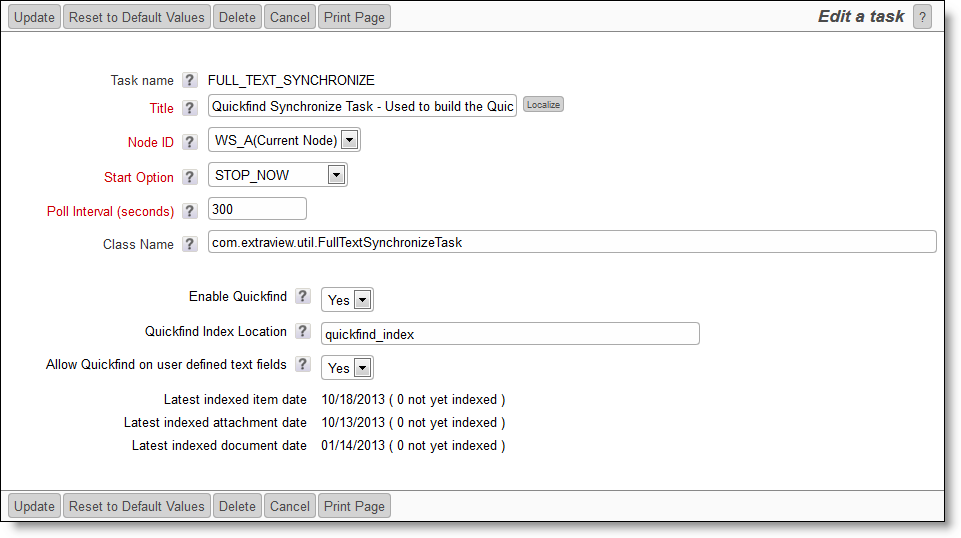
The Quickfind task management utility
If you are enabling Quickfind on an existing installation, you should index all the existing information by using the external program named FullTextIndexSetup. This should be accomplished with the task named Quickfind Synchronization Task (FULL_TEXT_SYNCHRONIZE) turned off, or the ExtraView application stopped. Some upgrades may also require the indexes to be rebuilt, using the same FullTextIndexSetup program.
The FullTextIndexSetup utility is extremely quick on a new database, but may take some time on a very large existing database. It is difficult to predict exactly how long this will take on a large database, as there are many factors such as the processing speed, memory, amount of text, and the amount of attachments that all have an impact. However, it is unlikely that the process will take more than a few hours. Your users can continue working during this period, and the search results will improve as the process continues. Our recommendation is to start the process after the majority of users leave work for the day.
The utility is found in the directory named WEB-INF/data.
The syntax to run this utility is:
For Windows platforms -
FullTextIndexSetup.bat JAVA_HOME TOMCAT_HOME EV_BASE
where JAVA_HOME is the path to your Java, TOMCAT_HOME is the path to your application server and
EV_BASE is the path to the ExtraView installation
or for Linux platforms -
FullTextIndexSetup.sh evj
where evj is the path to the ExtraView installation
Alter the script to set environment variables set for JAVA_HOME and TOMCAT_HOME
in the shell script file if needed.
The following are indexed as part of Quickfind's operations.
There are two text extractors:
As stated above, Quickfind utilizes the Apache Lucene software to provide the indexing mechanism. One support issue is that if your Java Virtual Machine, or your application server (Apache Tomcat or whatever) crashes for any reason, then the indexes may be left in a locked state on the server. The lock files are kept in the directory specified by the org.apache.lucene.lockdir system property if it is set, or by default in the directory specified by the java.io.tmpdir system property (on Unix boxes this is usually /var/tmp or /tmp). If for some reason java.io.tmpdir is not set, then the directory path you specified to create your index is used. Lock files have names that start with lucene- followed by an MD5 hash of the index directory path. If you are certain that a lock file is not in use, you can delete it manually.